大數據與數據挖掘的相對絕對關系
數據不是信息,而是有待理解的原材料。但有一件事是確定無疑的:當NSA為了從其海量數據中“挖掘”出信息,耗資數十億改善新手段時,它正受益于陡然降落的計算機存儲和處理價格。
麻省理工學院的研究者約翰·古塔格(John Guttag)和柯林·斯塔爾茲(Collin Stultz)創建了一個計算機模型來分析之心臟病病患丟棄的心電圖數據。他們利用數據挖掘和機器學習在海量的數據中篩選,發現心電圖中出現三類異常者——一年內死于第二次心臟病發作的機率比未出現者高一至二倍。這種新方法能夠識別出更多的,無法通過現有的風險篩查被探查出的高危病人。
數據挖掘這一術語含義廣泛,指代一些通常由軟件實現的機制,目的是從巨量數據中提取出信息。數據挖掘往往又被稱作算法。
威斯康星探索學院主任大衛·克拉考爾(David Krakauer)說,數據量的增長——以及提取信息的能力的提高——也在影響著科學。“計算機的處理能力和存儲空間在呈指數增長,成本卻在指數級下降。從這個意義上來講,很多科學研究如今也遵循摩爾定律。”
在 2005年,一塊1TB的硬盤價格大約為1,000美元,“但是現在一枚不到100美元的U盤就有那么大的容量。”研究智能演化的克拉考爾說。現下關于大數據和數據挖掘的討論“之所以發生是因為我們正處于驚天動地的變革當中,而且我們正以前所未有的方式感知它。”克拉勞爾說。
隨著我們通過電話、信用卡、電子商務、互聯網和電子郵件留下更多的生活痕跡,大數據不斷增長的商業影響也在如下時刻表現出來:
◆你搜索一條飛往塔斯卡魯薩的航班,然后便看到網站上出現了塔斯卡魯薩的賓館打折信息
◆你觀賞的電影采用了以幾十萬G數據為基礎的計算機圖形圖像技術
◆你光顧的商店在對顧客行為進行數據挖掘的基礎上獲取最大化的利潤
◆用算法預測人們購票需求,航空公司以不可預知的方式調整價格
◆智能手機的應用識別到你的位置,因此你收到附近餐廳的服務信息
互聯網上的火眼金睛
當醫學家忙于應對癌癥、細菌和病毒之時,互聯網上的政治言論已呈燎原之勢。整個推特圈上每天要出現超過 5 億條推文,其政治影響力與日俱增,使廉潔政府團體面臨著數據挖掘技術帶來的巨大挑戰。
印第安納大學 Truthy (意:可信)項目的目標是從這種每日的信息泛濫中發掘出深層意義,博士后研究員埃米利奧 · 費拉拉( Emilio Ferrara )說。 “Truthy 是一種能讓研究者研究推特上信息擴散的工具。通過識別關鍵詞以及追蹤在線用戶的活動,我們研究正在進行的討論。 ”
Truthy 是由印第安納研究者菲爾 · 孟澤( Fil Menczer )和亞力桑德羅 · 弗拉米尼( Alessandro Flammini )開發的。每一天,該項目的計算機過濾多達 5 千萬條推文,試圖找出其中蘊含的模式。
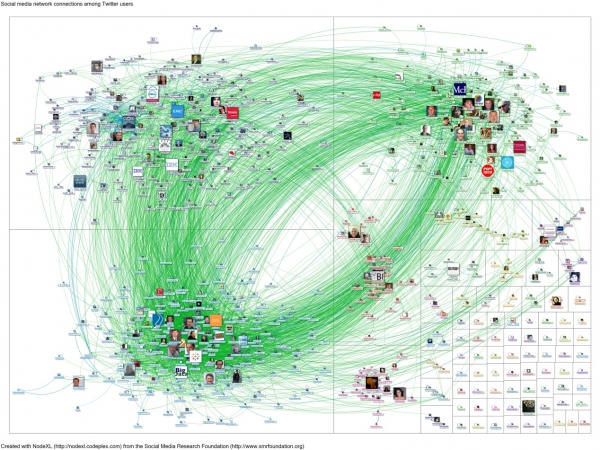
Truthy是由印第安納研究者菲爾·孟澤(Fil Menczer)和亞力桑德羅·弗拉米尼(Alessandro Flammini)開發的。每一天,該項目的計算機過濾多達5千萬條推文,試圖找出其中蘊含的模式。
大數據盯著“#bigdata”(意為大數據)。這些是在推特上發布過“bigdata”的用戶之間的連接,用戶圖標的尺寸代表了其粉絲數多寡。藍線表示一次回復或者提及,綠線表示一個用戶是另一個的粉絲。
一個主要的興趣點是“水軍”,費拉拉說:協調一致的造勢運動本應來自草根階層,但實際上是由“熱衷傳播虛假信息的個人和組織”發起的。
2012年美國大選期間,一系列推文聲稱共和黨總統候選人米特·羅姆尼(Mitt Romney)在臉譜網上獲得了可疑的大批粉絲。“調查者發現共和黨人和民主黨人皆與此事無關。”費拉拉說,“幕后另有主使。這是一次旨在令人們相信羅姆尼在買粉從而抹黑他的造勢運動。”
水軍的造勢運動通常很有特點,費拉拉說。“要想發起一場大規模的抹黑運動,你需要很多推特賬號,”包括由程序自動運行、反復發布選定信息的假賬號。“我們通過分析推文的特征,能夠辨別出這種自動行為。”
推文的數量年復一年地倍增,有什么能夠保證線上政治的透明呢?“我們這個項目的目的是讓技術掌握一點這樣的信息。”費拉拉說,“找到一切是不可能的,但哪怕我們能夠發現一點,也比沒有強。”
隨著數據及通訊價格持續下跌,新的思路和方法應運而生。
如果你想了解你家中每一件設備消耗了多少水和能量,麥克阿瑟獎獲得者西瓦塔克·帕特爾 (Shwetak Patel)有個解決方案:用無線傳感器識別每一臺設備的唯一數字簽名。帕特爾的智能算法配合外掛傳感器,以低廉的成本找到耗電多的電器。位于加利福尼亞 州海沃德市的這個家庭驚訝地得知,錄像機消耗了他們家11%的電力。等到處理能力一次相對較小的改變令結果出現突破性的進展,克拉考爾補充道,大數據的應用可能會經歷一次“相變”。
“大數據”是一個相對的說法,不是絕對的,克拉考爾指出。“大數據可以被視作一種比率——我們能計算的數據比上我們必須計算的數據。大數據一直存在。如果你想一下收集行星位置數據的丹麥天文學家第谷布拉赫(Tycho Brahe,1546-1601),當時還沒有解釋行星運動的開普勒理論,因此這個比率是歪曲的。這是那個年代的大數據。”
大數據成為問題“是在技術允許我們收集和存儲的數據超過了我們對系統精推細研的能力之后。”克拉考爾說。
我們好奇,當軟件繼續在大到無法想象的數據庫上執行復雜計算,以此為基礎在科學、商業和安全領域制定決策,我們是不是把過多的權力交給了機器。在我們無法覷探之處,決策在沒人理解輸入與輸出、數據與決策之間的關系的情況下被自動做出。“這正是我所從事的領域,”克拉考爾回應道,“我的研究對象是宇宙中的智能演化,從大爆炸到大腦。我毫不懷疑你說的。”
本文來源:大數據中國 節選
?
本文被轉載2次
首發媒體 | 轉發媒體
| 轉發媒體

