公眾號/?
編輯 | 蘿卜皮

來自深度語言模型的蛋白質表征,已經在計算蛋白質工程的許多任務中表現出最先進的性能。近年來,進展主要集中在參數計數上,最近模型的容量超過了它們所訓練的數據集的大小。
牛津大學(University of Oxford)的研究人員提出一個替代方向。他們證明,在密碼子而不是氨基酸序列上訓練的大型語言模型可以提供高質量的表征,并且在各種任務中都優于同類最先進的模型。
在某些任務中,例如物種識別、蛋白質和轉錄本豐度預測等,該團隊發現,基于密碼子訓練的語言模型優于所有其他已發布的蛋白質語言模型,包括一些包含超過 50 倍訓練參數的 模型 。
該研究以「Codon language embeddings provide strong signals for use in protein engineering」為題于 2024 年 2 月 23 日發布在《Nature Machine Intelligence》。

蛋白質表征學習仍存在不少挑戰
預訓練語言模型已成為計算蛋白質工程許多領域不可或缺的工具。大多數標記蛋白質數據集的大小有限,因此首先在大型、未標記的序列信息語料庫(例如 UniRef)上對龐大的深度神經網絡進行預訓練,并具有自監督的重建目標。自監督訓練賦予模型的潛在變量具有高度信息性的特征,稱為表征學習,然后可以在可用訓練數據有限的下游任務中利用這些特征。
蛋白質表征學習目前是用于預測變異適應性、蛋白質功能、亞細胞定位、溶解度、結合位點、信號肽、翻譯后修飾、內在紊亂等的最先進工具的核心,它們在實現準確的免比對蛋白質結構預測的道路上顯示出了巨大潛力。因此,改進學習表征是在計算蛋白質工程中實現一致、實質性改進的潛在途徑。
迄今為止,實現更多信息表征的途徑遵循兩個主要方向:追求增強規模的模型,其中增加模型容量單調地提高性能;模型架構的改進也持續帶來了性能提升。但是,這兩個方向都耗費人力和計算機時間,需要顯著優化,并且似乎提供遞減(對數)回報。
更豐富的數據是另一條途徑
改進學習表征的另一種途徑可能是使用包含更豐富信號的生物數據。雖然蛋白質語言模型迄今為止主要關注氨基酸序列,但編碼蛋白質的 DNA 序列中還包含其他信息。
蛋白質編碼 DNA (cDNA) 的語言依賴于 64 個核苷酸三聯體,稱為密碼子,每個密碼子編碼一個特定的氨基酸或序列的末端。
雖然這種 64 密碼子字母表是高度簡并的,大多數氨基酸由多達 6 個不同的密碼子編碼,但目前的研究表明,編碼相同氨基酸(同義)的密碼子不能互換使用。同義密碼子的使用與蛋白質結構特征相關,近 60 個同義突變與人類疾病有關。

圖示:將蛋白質語言模型擴展到密碼子語言。(來源:論文)
密碼子的使用也與蛋白質折疊有關,有充分的證據表明密碼子序列的變化會影響折疊動力學、折疊途徑,甚至正確折疊的蛋白質的量。這一證據表明,同義密碼子的使用包含有價值的生物信息,機器學習模型可以利用這些信息來提高預測任務中的信噪比。
用密碼子序列,而不是氨基酸序列
在最新的研究中,牛津大學的研究團隊證明在密碼子序列上預訓練蛋白質語言模型 CaLM(codon adaptation language model,由 8600 萬參數進行訓練),可以產生能夠捕獲關鍵生化特征的信息豐富的蛋白質表征。測試表明,根據密碼子而不是氨基酸序列訓練的蛋白質表征,在各種下游任務中表現出顯著的優勢。
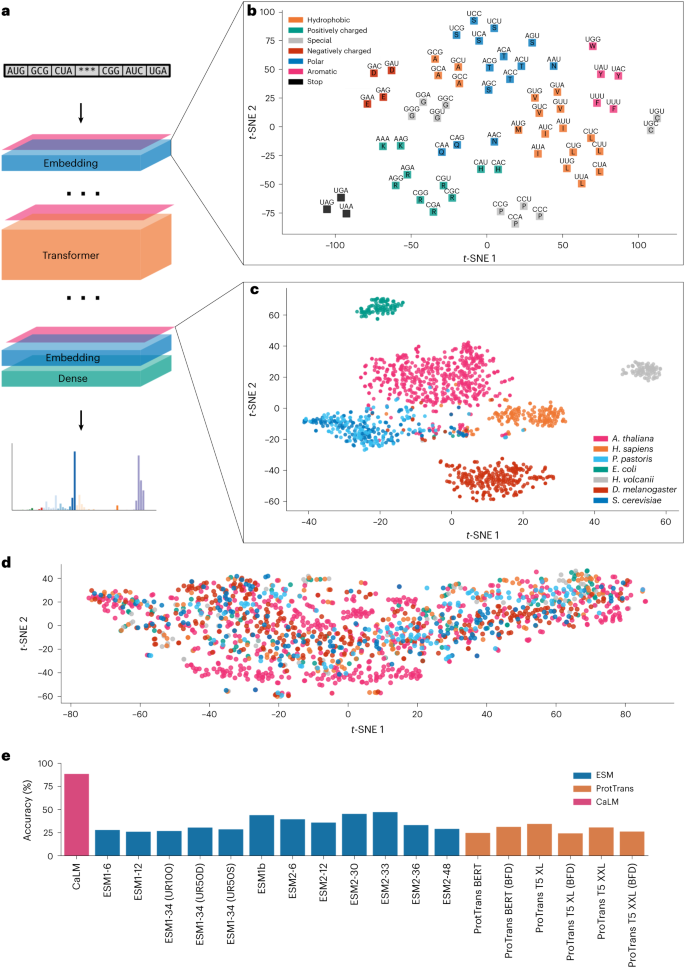
圖示:CaLM 概述。(來源:論文)
該團隊的 8600 萬參數語言模型的性能,優于其他具有類似容量的模型,在許多情況下,甚至優于參數超過 50 倍的模型。這種性能是由于密碼子語言模型能夠捕獲跨 DNA 序列的密碼子使用模式的能力,并且當密碼子使用信息被損壞時,這種優勢就會消失。
cDNA 訓練模型的額外訓練成本可以忽略不計,并且似乎可以提高所考慮的所有序列級任務的性能。由于高通量蛋白質測序幾乎完全是通過 DNA 序列的翻譯來完成的,因此原始編碼序列是公開可用的并且可以用于訓練。研究人員建議使用 cDNA 而不是簡單的氨基酸序列來訓練蛋白質語言模型,這為改進計算蛋白質工程提供了一條明確的途徑。
密碼子語言模型還可以為無需比對的蛋白質結構預測,提供有價值的進化信號,特別是在依賴語言模型來預測蛋白質各部分之間關系的 ESMfold 和 OmegaFold 等方法中。
基于 cDNA 的模型可以恢復更廣泛的進化關系,例如同義突變,這在核苷酸水平上很明顯,但在氨基酸水平上并不明顯。已知同義密碼子的使用與結構特征相關,并且密碼子使用和蛋白質折疊之間的聯系可能為已知無法捕獲折疊物理原理的方法提供有價值的信號。
研究人員建議,將密碼子語言模型納入免比對蛋白質結構預測的流程中,很可能為加速高精度蛋白質結構預測提供一條成本可以忽略不計的途徑。
提高蛋白質表達質量的兩個方向
該團隊還提出了進一步提高蛋白質表達質量的兩個主要方向。
一是規模擴大。當前的研究使用了一個只有 8600 萬個參數的簡單模型,這個大小與最新出版物中的標準模型大小相比顯得相形見絀。
使用的數據集也相對較小:與 ESM 系列模型中使用的 1.25 億個序列或某些 ProtTrans 模型中使用的近 5 億個序列相比,僅 900 萬個序列。通過在包含數億 DNA 序列的數據集上訓練數十億參數模型,存在一條明確的途徑來提高表征質量。
另一個潛在的改進方向是開發結合氨基酸和編碼序列的多模式模型。該研究的消融實驗表明,在缺乏密碼子使用信息的情況下,模型性能大幅下降,以至于低于數據集中的每個氨基酸模型。然而,由于模型間接訪問氨基酸序列,因此原則上它應該能夠訪問與僅氨基酸模型相同的信息。
這種差異可能是由于訓練期間缺乏氨基酸水平信號造成的,因此結合氨基酸和密碼子序列的訓練模型可以提高整體模型性能。
更豐富的輸入帶來新視角
在生物學中,人們非常關注數據集偏差的影響,但相比之下,人們很少甚至沒有關注蛋白質工程中更豐富的輸入的重要性。隨著計算能力和模型架構的進步,利用更豐富的生物數據為提高生物學中機器學習的能力提供了明確的方向。
基于 cDNA 訓練的大型語言模型的開發,將使研究「不直接由氨基酸序列確定的蛋白質特性」成為可能。例如,密碼子的使用與蛋白質折疊的相關性,實驗證據表明密碼子序列的變化確實會影響折疊動力學、折疊途徑,甚至正確折疊蛋白質的數量。
仔細選擇密碼子序列是蛋白質科學的一個關鍵目標,其中表達的 cDNA 的特定序列會對產量產生巨大影響。該團隊提出的基于密碼子的語言模型,代表了使用機器學習方法來研究蛋白質的這些特性和其他特性的第一步,而這些特性迄今為止還沒有被氨基酸語言模型解決。
相關報道:https://www.nature.com/articles/s42256-024-00791-0