華瑞指數云ExponTech聯合合作伙伴在硅谷發布新型AI存儲方案
全球AI的頂級盛會GTC于3月17日到3月21日在美國硅谷盛大舉行。在GTC大會期間,華瑞指數云ExponTech CTO曹羽中受邀參加了專注于AI Storage的技術研討會并發表演講。在演講中,曹羽中介紹了ExponTech與合作伙伴ScaleFlux, AIC基于英偉達的BlueField3 DPU以及英偉達最新發布的Spectrum-X網絡打造的新型AI Storage方案,展示了該方案的實際測試數據,并與合作伙伴,AI Storage行業專家以及一些大型客戶進行了深入討論。與會的專家均表示該方案的實測性能數據以及綜合優勢表現遠超預期,具備很高的 商業 價值,very impressive!

新型AI存儲方案采用的軟硬件方案:
硬件:
F2026 AI服務器,是一臺2U閃存JBOF,配備2個或4個NVIDIA BlueField-3數據處理單元(DPU)和24塊高性能ScaleFlux CSD5000 NVMe SSD(CSD5000是ScaleFlux公司最新推出的一款內置硬件壓縮與解壓縮能力的高性能NVMe SSD介質);
NVIDIA Spectrum-X網絡交換機;
軟件:
華瑞指數云ExponTech下一代分布式存儲軟件平臺WADP (WiDE AI Data Platform);

(本方案采用的2U存儲節點及ScaleFlux CSD5000 NVMe SSD)
基于此方案的AI訓練和推理環境的實測部署架構如下圖:

1臺2U AIC JBOF作為存儲服務器, 配備4塊NVIDIA BlueField3 DPU, 提供1600Gbps網絡帶寬,24塊ScaleFlux CSD5000 NVMe SSD,ExponTech WADP存儲軟件的后端運行于BlueField3 DPU內;
1臺標準2U服務器作為計算服務器,配備4塊NVIDIA BlueField3 DPU,提供800Gbps網絡帶寬,在DPU內部運行ExponTech WADP存儲軟件的存儲網關和協議;
計算服務器上可以配置GPU,用于訓練或推理,存儲軟件和網絡流量運行于DPU內,存儲IO不會消耗計算服務器的CPU和內存資源,計算服務器可以擁有更充沛的資源用于計算處理;
測試環境特別選擇了4臺NVIDIA Spectrum-X交換機組成兩層網絡,主要是為了模擬與驗證在大規模組網的情況下,RoCE網絡是否依然可以很好的處理擁塞,存儲軟件可以依然保持穩定的存儲性能和低時延;
存儲服務器(JBOF)和計算服務器均可以按需獨立擴展,按需加入更多的存儲服務器(JBOF)或者計算服務器,構成大規模的,存算分離的,按需擴展的AI訓練和推理集群。
基礎存儲性能驗證:
基于上一節所述的實測部署環境,進行了存儲系統的基礎性能驗證,其驗證方法是從計算節點上運行FIO,測試存儲系統的基礎性能指標。
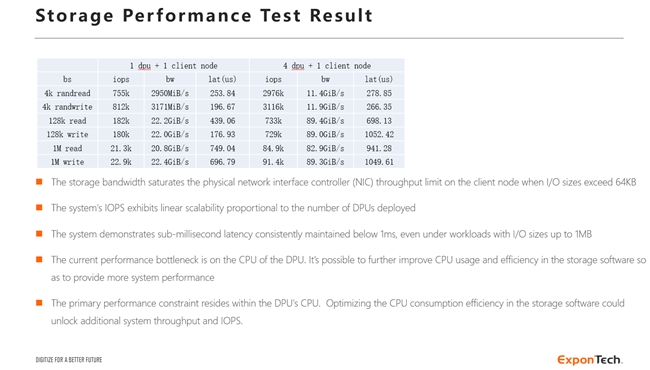
單個計算節點可以達到近90GB/s的存儲帶寬,接近計算節點網卡的物理帶寬上限;
單個計算節點可以達到310萬IOPS,當配置更多的計算節點時,可以同步獲得更多的IOPS。考慮到整個存儲系統的后端以及協議端都是跑在DPU內,DPU內的CPU處理性能遠遠不如服務器配置的CPU,單個計算節點+單個存儲節點即達到310萬IOPS已經充分展現了本方案相當驚人的IO處理效率;
存儲系統的IOPS與存儲節點上部署的數據處理單元(DPU)數量呈線性比例擴展,系統的IOPS隨DPU部署數量線性擴展,表明其具備極佳的橫向擴展能力。本方案采用的存儲節點最多可以配置8張DPU(當前測試環境配置4張),還可以實現IOPS性能翻倍以及網絡帶寬翻倍;
存儲系統在使用小IO size時,并發大壓力時延低至266us, 在使用大IO size時,打滿計算節點的網絡物理帶寬,時延還能始終保持在1毫秒以下。
MLPerf ?Storage v1.0測試結果:
MLPerf? 是影響力最廣的國際AI性能基準評測,MLPerf? Storage是針對AI Storage的基準性能測試,可以較為全面的評估測試AI應用程序的存儲需求。MLPerf? Storage基準測試通過運行一個分布式訓練測試程序,模擬GPU計算過程,在此過程中真實的執行AI服務器對存儲系統的讀寫訪問,以此來測試存儲系統能夠支撐的最大GPU數量和帶寬表現。
MLPerf Storage v1.0于2024年8月推出,國內外一共有十三家從事高性能存儲研發的廠家參與了測試并提交正式測試結果,其中包括DDN(Lustre),華為,WekaIO,Hammerspace等知名的分布式文件系統廠家。
本次我們選擇了ResNet50模型(主要用于圖像分類和圖像識別場景),在上述1存儲節點(JBOF)+1計算節點的測試環境上進行了MLPerf Storage v1.0基準測試,測試的結果如下:
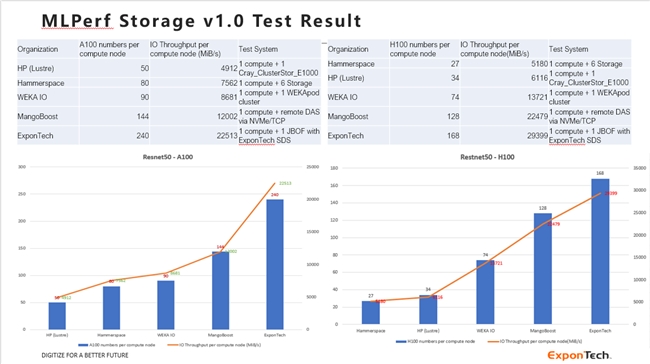
測試結果表明:
ExponTech 的新型AI存儲方案 具備全球領先的性能,單客戶端能夠支持的GPU卡的數量超過了所有參與了MLPerf Storage v1.0正式測試的廠商, 位居全球第一 ;單客戶端能夠實現的存儲帶寬達到近30GB/s,? 位居全球第二 ;本次測試環境只有一個客戶端節點(計算節點),CPU和內存配置較低,在運行MLPerf Storage v1.0的測試中已經達到了客戶端節點的計算能力的瓶頸,但是還遠遠沒有達到存儲節點的存儲能力的瓶頸。 如果換用處理能力更強的計算節點來做測試,可以測試出更高的性能數據,即支持更多的GPU卡,實現更高的存儲帶寬。
總結
基于本次在真實的環境上的全面測試,總結一下ExponTech與合作伙伴ScaleFlux, AIC基于英偉達的BlueField3 DPU以及英偉達最新發布的Spectrum-X網絡打造的新型AI Storage方案的關鍵特點和優勢:
世界頂級性能, SPC-1 評測超越所有高端全閃存儲陣列,打破世界紀錄,MLPerf Storage v1.0測試數據大幅度超越WekaIO, DDN等著名并行文件系統;
世界頂級容量密度, 當前每2U Storage Node可實現超過1.6PB存儲裸容量,明年可擴展至每2U超過6.6PB,最大化數據中心空間的AI數據價值;
配置的ScaleFlux CSD5000 NVMe SSD具有盤內透明壓縮解壓縮能力,能夠在不消耗額外系統資源, 不影響性能的情況下實現存儲 裸 容量的數倍放大,存儲容量效率獲得驚人的提升;
同一平臺上同時支持高性能分布式塊存儲和文件存儲等多種協議,除了支持AI的訓練和推理場景,還可以覆蓋數據匯集,數據準備,RAG等AI Pipeline全場景,無須為AI Pipeline配置不同的存儲方案以及反復進行數據拷貝移動, 可以實現AI 算力和存力 的 完全存算分離 和獨立擴展,具備更好的可管理性和效率;
強大的并行擴展性, 存儲節點及計算節點均可以獨立的水平擴展,同時實現存儲性能和容量的等比例擴展;
可靠性高,可維護性高, 存儲節點采用相比標準服務器更為精簡的JBOF,硬件故障率更低,同時JBOF內部采用冗余的硬件設計來保障可靠性,提升可維護性;
支持基于RoCE的超大規模組網,采用RoCE動態路由和細粒度的負載均衡實現更好的擁塞控制, 基于標準以太網在大規模RDMA組網中實現高效帶寬, 低抖動和超低時延;
優化的總體擁有成本(TCO),高密度的存儲節點+透明盤內壓縮+新型軟件定義存儲軟件的組合簡化了硬件成本,大幅度提升了存儲空間利用效率和讀寫性能,簡化了管理, AI客戶將因此大幅度優化其AI Storage的總體擁有成本(TCO);
基于此方案的KV Cache大規模持久化方案也即將推出,實現AI推理集群內的K,V向量的全局共享,能夠以低成本高性能的大規模存儲能力替代AI推理過程中K,V向量的大量重復運算, 實現AI推理 算力成本 的大幅降低。




