2023年電信AI公司頂會論文及競賽分享
近年來,中國電信在人工智能技術(shù)方向持續(xù)發(fā)力。2023年11月28日,中國電信數(shù)字智能 科技 分公司正式更名為中電信人工智能科技有限公司(以下簡稱“電信AI公司”)。2023年,電信AI公司連續(xù)在21項國內(nèi)外頂級AI競賽中獲獎,申請專利100余項,同時在CVPR、ACM MM、ICCV等頂級會議和期刊上發(fā)表論文30余篇,彰顯了國資央企在人工智能技術(shù)領(lǐng)域布局的初步成效。
電信AI公司作為中國電信開展人工智能業(yè)務(wù)的科技型、能力型、平臺型專業(yè)公司,專注于人工智能核心技術(shù)攻堅、前沿技術(shù)研究和和產(chǎn)業(yè)空間拓展,以成為百億級人工智能服務(wù)商為發(fā)展目標。在過去兩年時間,電信AI公司成功自主研發(fā)了星河AI算法倉賦能平臺、星云AI四級算力平臺、星辰通用基礎(chǔ)大模型等一系列創(chuàng)新應(yīng)用成果。公司現(xiàn)有人員800+,平均年齡31歲,其中80%為研發(fā)人員,70%來自于國內(nèi)外 互聯(lián)網(wǎng) 大廠和AI頭部企業(yè)。為全面加速大模型時代的研發(fā)進度,公司現(xiàn)有A100等效算力的訓(xùn)練卡2500+,專職數(shù)據(jù)標注人員300+,聯(lián)合上海人工智能實驗室、西安交通大學(xué)、北京郵電大學(xué)、智源研究院等科研院所,面向中國電信6000萬視聯(lián)網(wǎng)和數(shù)億用戶場景,共同打造國際一流的人工智能技術(shù)和落地應(yīng)用。
接下來,我們將對電信AI公司在2023年的一些重要科研成果進行系列回顧和分享。本期介紹AI研發(fā)中心CV算法團隊在ICCV 2023 獲得Temporal Action Localisation賽道冠軍的技術(shù)成果。ICCV是國際計算機視覺領(lǐng)域的三大頂會之一,每兩年召開一次,在業(yè)內(nèi)具有極高的評價。本文將分享該團隊在本次挑戰(zhàn)中采用的算法思路和方案。
ICCV 2023 The Perception Test Challenge-Temporal Action Localisation 冠軍技術(shù)分享

【賽事概覽與團隊背景】
DeepMind發(fā)起的ICCV 2023 The First Perception Test Challenge旨在通過探索模型在視頻、音頻和文本模態(tài)中的能力。競賽涵蓋了四個技能領(lǐng)域、四種推理類型和六個計算任務(wù),以更全面地評估多模態(tài)感知模型的能力。其中,Temporal Action Localisation賽道的核心任務(wù)是對未剪輯的視頻內(nèi)容進行深入理解和準確的動作定位,該技術(shù)對自動駕駛系統(tǒng)、視頻監(jiān)控分析等多種應(yīng)用場景具有重要意義。
由電信AI公司交通算法方向的成員組成的CTCV團隊,參加了本次比賽。電信AI公司在計算機視覺技術(shù)這個研究方向深耕,積累了豐富的經(jīng)驗,技術(shù)成果已在城市治理、交通治安等多個業(yè)務(wù)領(lǐng)域中廣泛應(yīng)用,持續(xù)服務(wù)海量的用戶。
1引言
在視頻中定位和分類動作的任務(wù),即時序動作定位(Temporal Action Localisation, TAL),仍然是視頻理解中的一個挑戰(zhàn)性問題。
近期TAL技術(shù)取得了顯著的進展。例如,TadTR和ReAct使用類似DETR的基于Transformer的解碼器進行動作檢測,將動作實例建模為一組可學(xué)習的集合。TallFormer使用基于Transformer的編碼器提取視頻表征。
雖然以上方法在時序動作定位方面已經(jīng)實現(xiàn)了較好的效果,但在視頻感知能力方面還存在局限性。想要更好地定位動作實例,可靠的視頻特征表達是關(guān)鍵所在。團隊首先采用VideoMAE-v2框架,加入adapter+linear層,訓(xùn)練具有兩種不同主干網(wǎng)絡(luò)的動作類別預(yù)測模型,并用模型分類層的前一層,進行TAL任務(wù)的特征提取。接下來,利用改進的ActionFormer框架訓(xùn)練TAL任務(wù),并修改WBF方法適配TAL任務(wù)。最終,CTCV團隊的方法在評測集上實現(xiàn)了0.50的mAP,排名第一,領(lǐng)先第二名的團隊3個百分點,比Google DeepMind提供的baseline高出34個百分點。
2 競賽解決方案

圖1 算法概覽
2.1 數(shù)據(jù)增強

在 Temporal Action Localisation賽道中,CTCV團隊使用的數(shù)據(jù)集是未經(jīng)修剪的用于動作定位的視頻,具有高分辨率,并包含多個動作實例的特點。通過分析數(shù)據(jù)集,發(fā)現(xiàn)訓(xùn)練集相較于驗證集缺少了三個類別的標簽,為保證模型驗證的充分性以及競賽的要求,團隊采集了少量的視頻數(shù)據(jù),并加入訓(xùn)練數(shù)據(jù)集中,以豐富訓(xùn)練樣本。同時為簡化標注,每個視頻預(yù)設(shè)只包含一個動作。
圖2 自主采集的視頻樣例
2.2 動作識別與特征提取
近年來,大規(guī)模數(shù)據(jù)進行訓(xùn)練的基礎(chǔ)模型噴涌而出,通過zero-shot recognition、linear probe、prompt finetune、fine-tuning等手段,將基礎(chǔ)模型較強的泛化能力應(yīng)用到多種下游任務(wù)中,有效地推動了AI領(lǐng)域多個方面的進步。
TAL賽道中的動作定位和識別十分具有挑戰(zhàn)性,例如‘假裝將某物撕成碎片’與‘將某物撕成碎片’動作極為相似,這無疑給特征層面帶來了更大的挑戰(zhàn)。因此直接借助現(xiàn)有預(yù)訓(xùn)練模型提取特征,效果不理想。
因此,該團隊通過解析JSON標注文件,將TAL數(shù)據(jù)集轉(zhuǎn)換為動作識別數(shù)據(jù)集。然后以Vit-B和Vit-L為主干網(wǎng)絡(luò),在VideoMAE-v2網(wǎng)絡(luò)后增加adapter層及用于分類的linear層,訓(xùn)練同數(shù)據(jù)域下的動作分類器,并將動作分類模型去掉linear層,用于視頻特征的提取。VitB模型的特征維度為768,而ViTL模型的特征維度為1024。同時concat這兩種特征時,新生成一個維度為1792的特征,該特征作為訓(xùn)練時序動作定位模型的備選。訓(xùn)練初期,團隊也使用了音頻特征,但實驗結(jié)果發(fā)現(xiàn)mAP指標有所下降。因此,在隨后的實驗中沒有考慮音頻特征。
2.3 時序動作定位
Actionformer是一個為時序動作定位設(shè)計的anchor-free模型,它集成了多尺度特征和時間維度的局部自注意力。本次競賽,CTCV團隊使用Actionformer作為動作定位的baseline模型,以預(yù)測動作發(fā)生的邊界(起止時間)及類別。
CTCV團隊將動作邊界回歸和動作分類任務(wù)進行統(tǒng)一。相比基線訓(xùn)練架構(gòu),首先編碼視頻特征到多尺度的Transformer中。然后在模型的回歸和分類的head分支引入feature pyramid layer,增強網(wǎng)絡(luò)特征表達,head分支在每個time step會產(chǎn)生一個action candidate。同時通過將head的數(shù)量增加到32,引入fpn1D結(jié)構(gòu),進一步提升了模型的定位與識別能力。
2.4 WBF for 1-D
Weighted Boxes Fusion(WBF)是一種新型的加權(quán)檢測框融合方法,該方法利用所有檢測框的置信度來構(gòu)造最終的預(yù)測框,并在圖像目標檢測中取得了較好的效果,與NMS和soft-NMS方法不同,它們會丟棄某些預(yù)測,WBF利用所有提出的邊界框的置信度分數(shù)來構(gòu)造平均盒子。這種方法極大地提高了結(jié)合預(yù)測矩形的準確性。
受WBF在物體檢測應(yīng)用的啟發(fā),CTCV團隊將動作的一維邊界框類比為一維線段,并對WBF方法進行了修改,以適用于TAL任務(wù),如圖3所示。實驗結(jié)果表明了該方法的有效性。
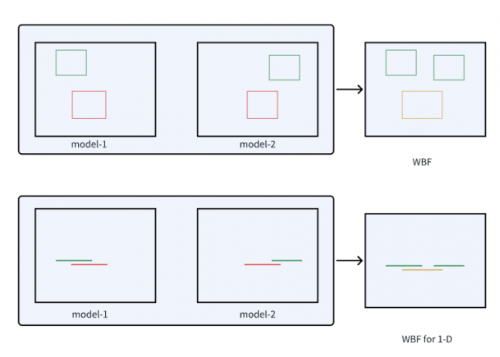
圖3 改進的1維WBF 示意圖
3 實驗結(jié)果
3.1 評估指標
本次挑戰(zhàn)賽使用的評估指標是mAP。它是通過計算不同動作類別和IoU閾值的平均精確度來確定的。CTCV團隊以0.1的增量評估IoU閾值,范圍從0.1到0.5。
3.2 實驗細節(jié)
為獲得多樣化的模型,CTCV團隊先對訓(xùn)練數(shù)據(jù)集進行80%的重復(fù)采樣5次,并分別采用Vit-B、Vit-L以及concat的特征,完成模型訓(xùn)練,得到了15個多樣化的模型。最后將這些模型的評估結(jié)果分別輸入WBF模塊,并為每個模型結(jié)果分配了相同的融合權(quán)重。
3.3 實驗結(jié)果
表1展示了不同特征的性能對比。第1行和第2行分別展示了使用ViT-B和ViT-L特征特征的結(jié)果。第3行是ViT-B和ViT-L特征級聯(lián)的結(jié)果。
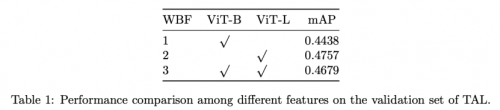
在實驗過程中,CTCV團隊發(fā)現(xiàn)級聯(lián)特征的mAP略低于ViT-L,但仍優(yōu)于ViT-B。盡管如此,基于各種方法在驗證集上的表現(xiàn),將不同特征在評測集的預(yù)測結(jié)果借助WBF進行融合,最終提交到系統(tǒng)的mAP為0.50。
4 結(jié)論
本次競賽中,CTCV團隊通過數(shù)據(jù)收集增強相對驗證集中缺失類別的訓(xùn)練數(shù)據(jù)。借助VideoMAE-v2框架加入adapter層訓(xùn)練視頻特征提取器,并利用改進的ActionFormer框架訓(xùn)練TAL任務(wù),同時修改了WBF方法以便有效地融合測試結(jié)果。最終,CTCV團隊在評測集上實現(xiàn)了0.50的mAP,排名第一。電信AI公司一直秉持著“技術(shù)從業(yè)務(wù)中來,到業(yè)務(wù)中去”的路線,將競賽視為檢驗和提升技術(shù)能力的重要平臺,通過參與競賽,不斷優(yōu)化和完善技術(shù)方案,為客戶提供更高質(zhì)量的服務(wù),同時也為團隊提供了寶貴的學(xué)習和成長機會。
本文被轉(zhuǎn)載1次
首發(fā)媒體 | 轉(zhuǎn)發(fā)媒體
| 轉(zhuǎn)發(fā)媒體